Kubernetes 组件
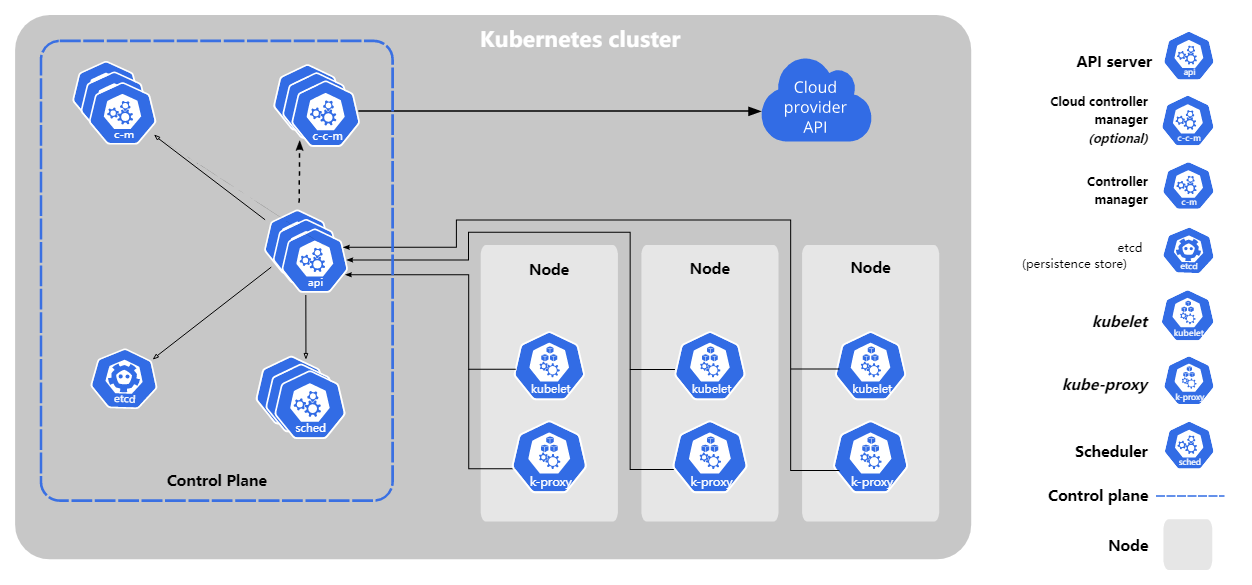
控制平面组件(Control Plane Components) – master
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。 请参阅使用 kubeadm 构建高可用性集群 中关于多 VM 控制平面设置的示例。
kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
kube-controller-manager
运行控制器进程的控制平面组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
cloud-controller-manager
云控制器管理器是指嵌入特定云的控制逻辑的 控制平面组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
cloud-controller-manager 仅运行特定于云平台的控制回路。 如果你在自己的环境中运行 Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器。
Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
kube-proxy
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。
Kubernetes 支持多个容器运行环境: Docker、 containerd、CRI-O 以及任何实现 Kubernetes CRI (容器运行环境接口)。
pod
Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。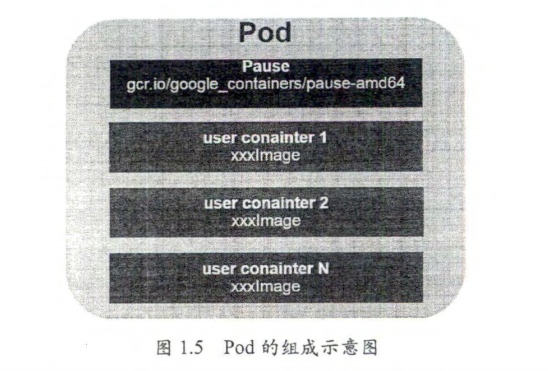
Pod 的共享上下文包括一组 Linux 名字空间、控制组(cgroup)和可能一些其他的隔离 方面,即用来隔离 Docker 容器的技术。 在 Pod 的上下文中,每个独立的应用可能会进一步实施隔离。
就 Docker 概念的术语而言,Pod 类似于共享名字空间和文件系统卷的一组 Docker 容器。
每个 Pod 都有一个特殊的被称为“根容器"的 Pause 容器 。Pause 器对应的镜像
属于 Kubernetes 平台的一部分,除了 Pause 容器,每个 Pod 都还包含一个或多个紧密相关
的用户业务容器。
- Kubernete 为每个 Pod 分配了唯一 IP 地址,称之为 Pod IP, 一个 Pod 里的 多个
容器共享 Pod IP 地址 Kubernetes 要求底层网络支待集群内任意两个 Pod 之间的 TCP/IP
直接通信,这通常采用虚拟二层网络技术实现,例如 Flannel Open vSwitch 等,因此我们
需要牢记一点 Kubernetes 里, 一个 Pod 里的容器与另外主机上的 Po 容器能够直接通
信。 - Pod 其实有两种类型:普通的 Pod 及静态 Pod (Static Pod)。
后者比较特殊,它并没被 存放在 Kubernetes etcd 中,而是被存放在某个具体的 Node 上的 一个具体文件中,并且
只能在此 Node 启动、运行。而普通的 Pod 旦被创建,就会被放入 etcd 中存储。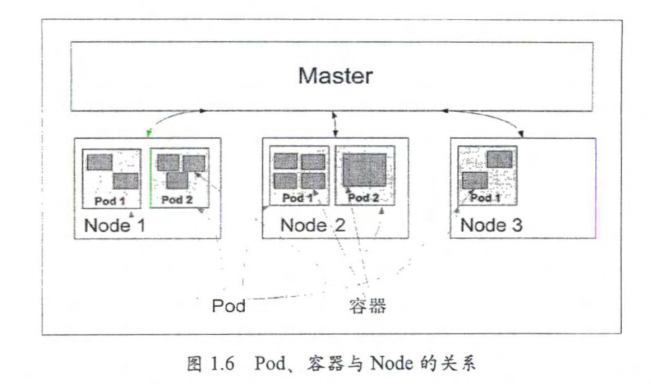
- Pod Volume, Pod Volume 是被定义在 Pod 上,然后被各个容器挂载到自己的文件系统中 的。 Volume 单来
说就是被挂载到 Pod 里的文件目录。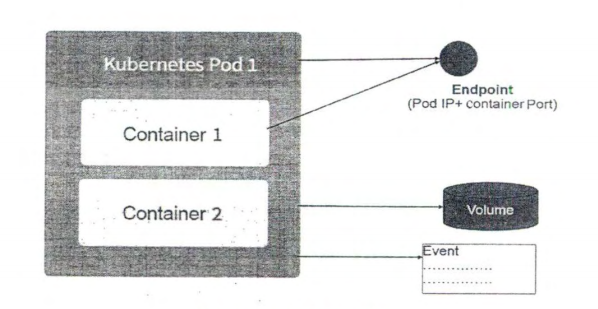
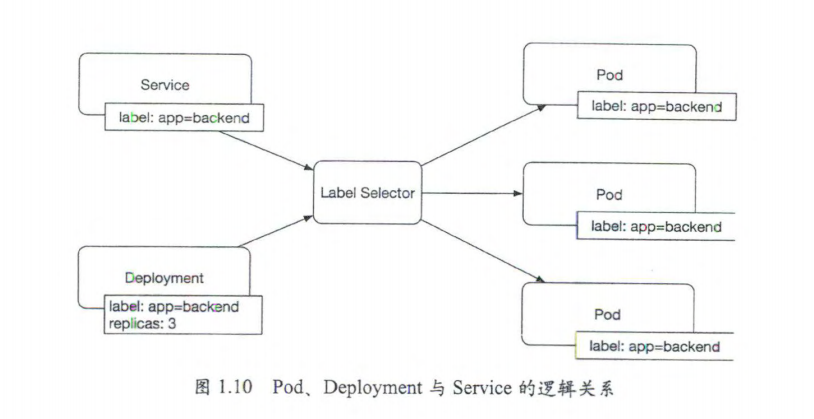
- pod 与 deployment
endpoint
Pod IP 加上这里的容器端口 (containerPort )
状态的应用集群
- StatefulSets
- StatefulSet 基础
StatefulSet 之前曾用过 PetSet 这个名称,很多人都知道,在
IT 世界里,有状态的应用被类比 宠物 Pet ,无状态的应用则被类比为牛羊,每个宠物
在主人那里都是“唯一的存在",宠物生病了,我们是要 很多钱去治疗 ,需要我们用
照料,而无差别 牛羊则没有这个待遇 总结下来,在有状态集群中一般有如下特殊共性 - 每个节点都有固定的身份 ID, 通过这个 ID 集群中的成员可以相互发现并通信
- 集群的规模是比较固定的,集群规模不能随意变动
- 集群中 每个节点都是有状态的,通常会待久 数据到永久存储中,每个节点在 重启后都需要使用原有的持久化数据
- 集群中成员节点的启动顺序(以及关闭顺序 )通常也是确定的
- 如果磁盘损坏,则集群里的某个节点无法正常运行,集群功能受损
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。
但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
- StatefulSet 里的每个 Pod 都有稳定 唯一的网络标识,可以用来发现集群内的其他成员
假设 StatefulSet 的名称为 kafka, 那么第1个 Pod 叫 kafka-0, 第2个叫 kafka-1,
以此类推 - StatefulSet 控制的 Pod 副本的启停顺序是受控的,操作第n个Pod 时,前 n-1 Pod 经是运行且准备好的状态
- StatefulSet Pod 采用稳定的持久化存储卷,通过 PV PVC 来实现,删除 Pod 默认不会删除与 StatefulSet 相关的存储卷 (为了保证数据安全)
批处理应用 Job
https://kubernetes.io/zh/docs/concepts/workloads/controllers/job/
ConfigMap 配置中心
https://kubernetes.io/zh/docs/concepts/configuration/configmap/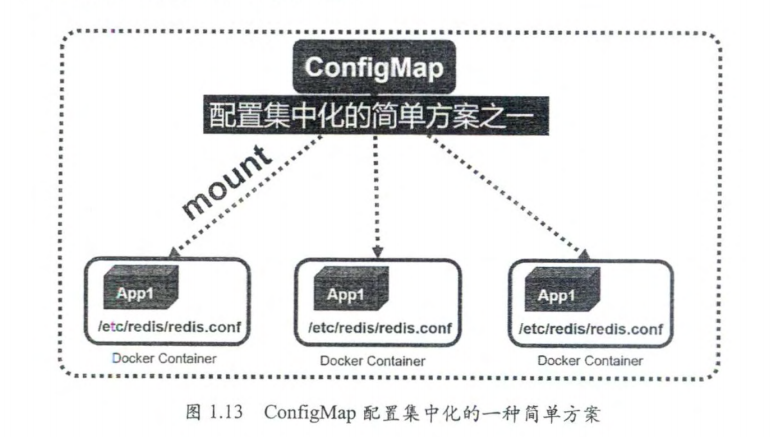
存储卷
卷
示例:使用 Persistent Volumes 部署 WordPress 和 MySQL