优先队列和堆
什么是二叉堆
二叉堆本质上是一种完全二叉树,它分为两个类型:
1.最大堆 任何一个父节点的值,都大于等于它左右孩子节点的值。 2.最小堆 任何一个父节点的值,都小于等于它左右孩子节点的值。
二叉堆的根节点叫做堆顶。 最大堆和最小堆的特点,决定了在最大堆的堆顶是整个堆中的最大元素;最小堆的堆顶是整个堆中的最小元素。
堆的代码实现
二叉堆虽然是一颗完全二叉树,但它的存储方式并不是链式存储,而是顺序存储。换句话说,二叉堆的所有节点都存储在数组当中。
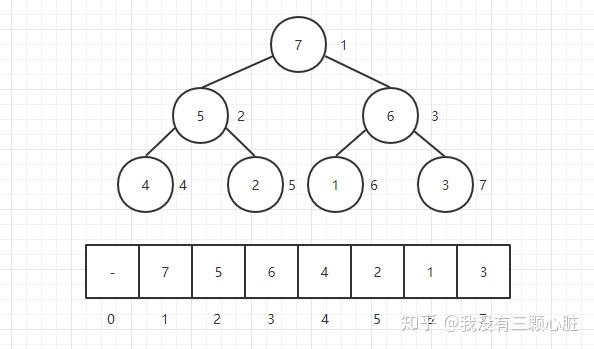
用数组来表示堆不仅不会浪费空间还具有一定的优势:
- 每个结点的左孩子为下标i的2倍:left child(i) = i * 2;每个结点的右孩子为下标i的2倍加1:right child(i) = i * 2 + 1
- 每个结点的父亲结点为下标的二分之一:parent(i) = i / 2,注意这里是整数除,2和3除以2都为1,大家可以验证一下;
- 注意:这里是把下标为0的地方空出来了的,主要是为了方便理解,如果0不空出来只需要在计算的时候把i值往右偏移一个位置就行了(也就是加1,大家可以试试,下面的演示也采取这样的方式);
堆的自我调整
对于二叉堆,如下有几种操作:
- 插入节点
- 删除节点
- 构建二叉堆
堆的基本结构
1 | public class MaxHeap<E extends Comparable<E>> { |
1.向堆中添加元素和Sift Up
当插入一个元素到堆中时,它可能不满足堆的性质,在这种情况下,需要调整堆中元素的位置使之重新变成堆,这个过程称为堆化(heapifying);在最大堆中,要堆化一个元素,需要找到它的父亲结点,如果不满足堆的基本性质则交换两个元素的位置,重复该过程直到每个结点都满足堆的性质为止,下面我们来模拟一下这个过程:
下面我们在该堆中插入一个新的元素26: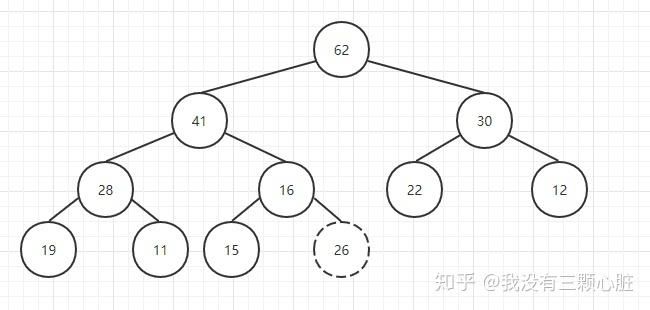
我们通过索引(上面的公式)可以很容易地找到新插入元素的父亲结点,然后比较它们的大小,如果新元素更大则交换两个元素的位置,这个操作就相当于把该元素上浮了一下: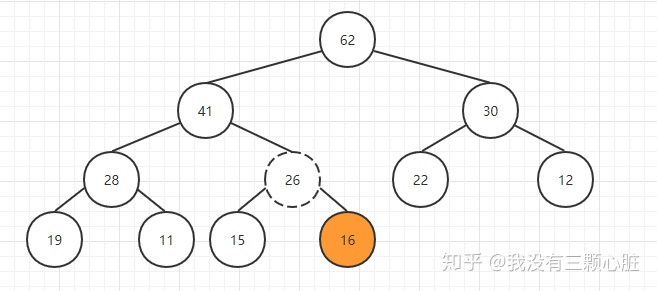
重复该操作直到26到了一个满足堆条件的位置,此时就完成了插入的操作: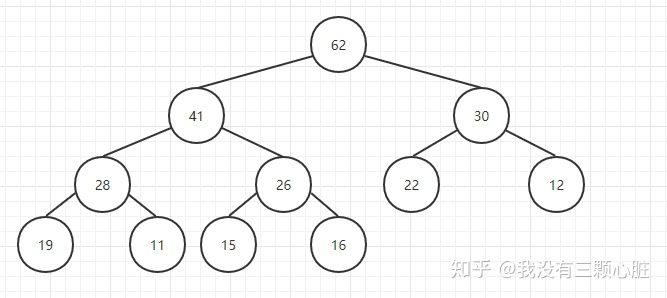
1 | // 向堆中添加元素public |
2.取出堆中的最大元素和Sift Down
如果理解了上述的过程,那么取出堆中的最大元素(堆顶元素)将变得容易,不过这里运用到一个小技巧,就是用最后一个元素替换掉栈顶元素,
然后把最后一个元素删除掉,这样一来元素的总个数也满足条件,然后只需要把栈顶元素依次往下调整就好了,这个操作就叫做Sift Down(下沉):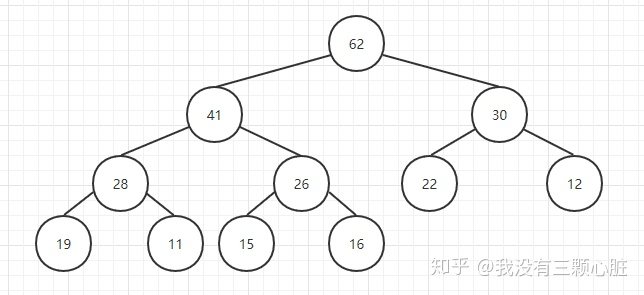
用最后元素替换掉栈顶元素,然后删除最后一个元素: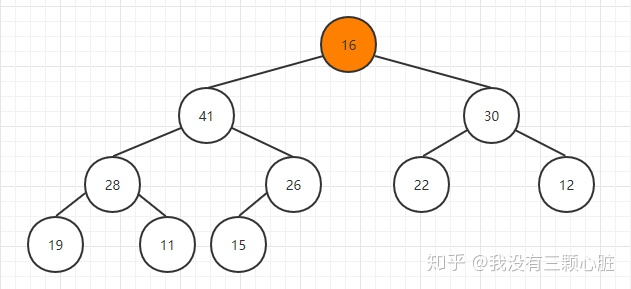
然后比较其孩子结点的大小: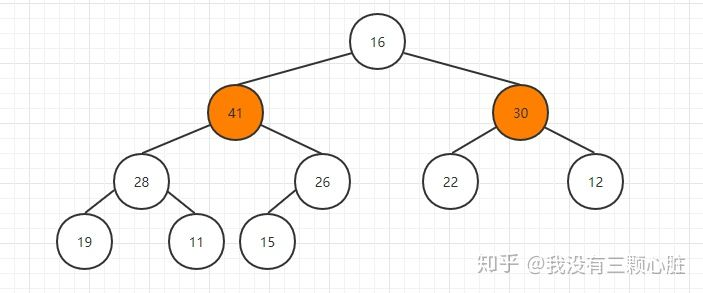
如果不满足堆的条件,那么就跟孩子结点中较大的一个交换位置: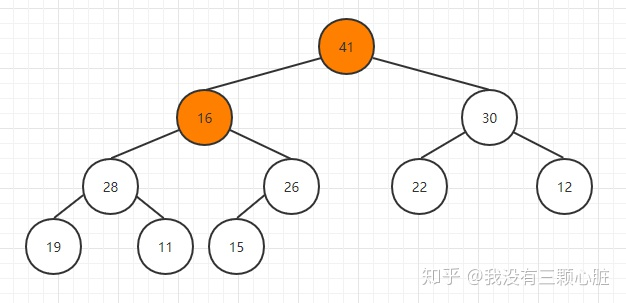
重复该步骤,直到16到达合适的位置: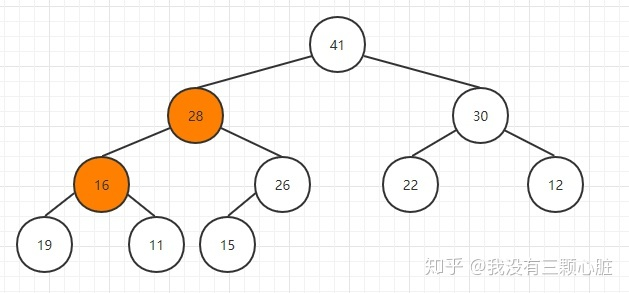
完成取出最大元素的操作: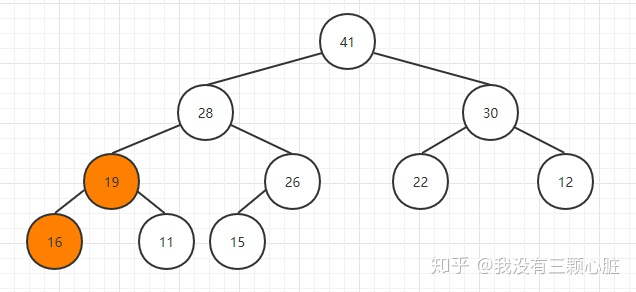
1 | 对应的代码如下: |
3.Replace 和 Heapify
Replace这个操作其实就是取出堆中最大的元素之后再新插入一个元素,
常规的做法是取出最大元素之后,再利用上面的插入新元素的操作对堆进行Sift Up操作,
但是这里有一个小技巧就是直接使用新元素替换掉堆顶元素,之后再进行Sift Down操作,这样就把两次O(logn)的操作变成了一次O(logn):
1 | // 取出堆中的最大元素,并且替换成元素e |
Heapify翻译过来就是堆化的意思,就是将任意数组整理成堆的形状,通常的做法是遍历数组从0开始添加创建一个新的堆,但是这里存在一个小技巧就是把当前数组就看做是一个完全二叉树,然后从最后一个非叶子结点开始进行Sift Down操作就可以了,最后一个非叶子结点也很好找,就是最后一个结点的父亲结点,大家可以验证一下: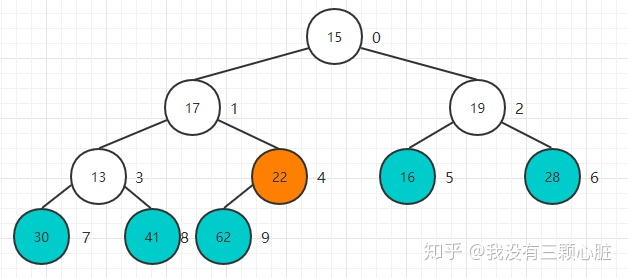
从22这个节点开始,依次开始Sift Down操作: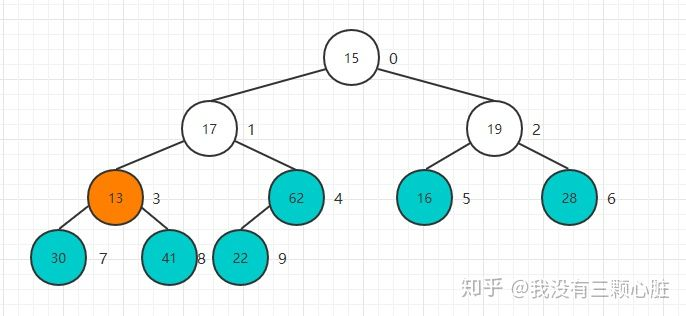
重复该过程直到堆顶元素: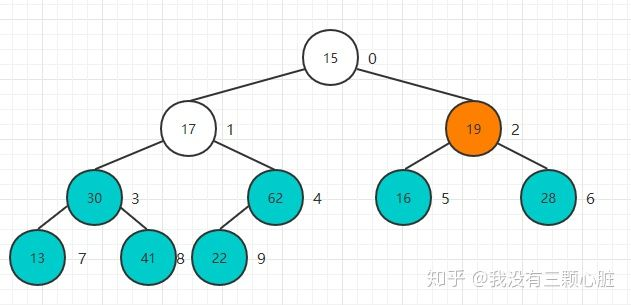
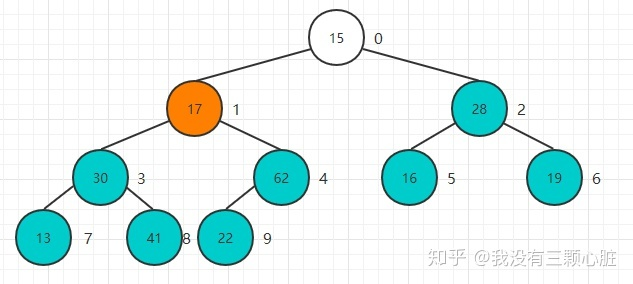
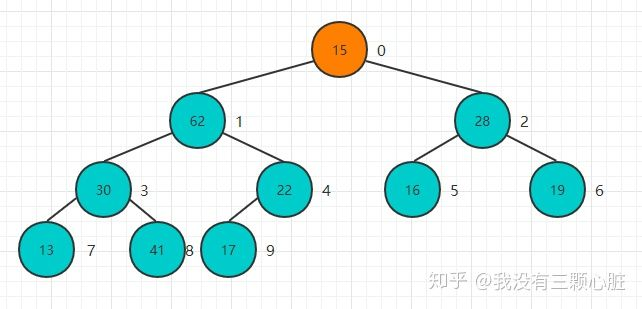
完成堆化操作: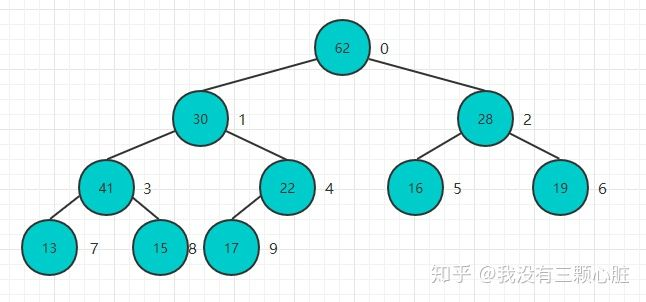
将n个元素逐个插入到一个空堆中,算法复杂度是O(nlogn),而heapify的过程,算法复杂度为O(n),这是有一个质的飞跃的,下面是代码:
1 | public MaxHeap(E[] arr){ |
什么是优先队列?
优先队列也是一种队列,只不过不同的是,优先队列的出队顺序是按照优先级来的;在有些情况下,可能需要找到元素集合中的最小或者最大元素,可以利用优先队列ADT来完成操作,优先队列ADT是一种数据结构,它支持插入和删除最小值操作(返回并删除最小元素)或删除最大值操作(返回并删除最大元素);
这些操作等价于队列的enQueue和deQueue操作,区别在于,对于优先队列,元素进入队列的顺序可能与其被操作的顺序不同,作业调度是优先队列的一个应用实例,它根据优先级的高低而不是先到先服务的方式来进行调度;
如果最小键值元素拥有最高的优先级,那么这种优先队列叫作升序优先队列(即总是先删除最小的元素),类似的,如果最大键值元素拥有最高的优先级,那么这种优先队列叫作降序优先队列(即总是先删除最大的元素);由于这两种类型时对称的,所以只需要关注其中一种,如升序优先队列;
优先队列ADT
下面操作组成了优先队列的一个ADT;
1.优先队列的主要操作 优先队列是元素的容器,每个元素有一个相关的键值;
- insert(key, data):插入键值为key的数据到优先队列中,元素以其key进行排序;
- deleteMin/deleteMax:删除并返回最小/最大键值的元素;
- getMinimum/getMaximum:返回最小/最大剑指的元素,但不删除它;
2.优先队列的辅助操作
- 第k最小/第k最大:返回优先队列中键值为第k个最小/最大的元素;
- 大小(size):返回优先队列中的元素个数;
- 堆排序(Heap Sort):基于键值的优先级将优先队列中的元素进行排序;
优先队列的应用
- 数据压缩:赫夫曼编码算法;
- 最短路径算法:Dijkstra算法;
- 最小生成树算法:Prim算法;
- 事件驱动仿真:顾客排队算法;
- 选择问题:查找第k个最小元素; 等等等等….
优先队列的实现比较
| 实现 | 插入 | 删除 | 寻找最小值 |
|---|---|---|---|
| 无序数组 | 1 | n | n |
| 无序链表 | 1 | n | n |
| 有序数组 | n | 1 | 1 |
| 有序链表 | n | 1 | 1 |
| 二叉搜索树 | logn(平均) | logn(平均) | logn(平均) |
| 平衡二叉搜索树 | logn | logn | logn |
| 二叉堆 | logn | logn | 1 |